معهد ماساتشوستس للتكنولوجيا ينشر بحثًا حول كيفية اكتشاف الأخبار المزيفة

اكتشف باحثون من معهد ماساتشوستس للتكنولوجيا، وجود عيب أساسي في معظم أدوات الكشف عن الأخبار المزيفة الحالية، والأساليب المحسنة المقترحة.
اليوم، أصبحت أساليب إنشاء أخبار مزيفة أكثر شيوعًا وتطوراً، حيث يمكن للعديد من منشئي النصوص المستندة إلى الذكاء الاصطناعي، بما في ذلك GPT-2 لـ Open AI، استخلاص قصص مثالية ومتماسكة تجعلهم يخدعون بسهولة.
ولتخفيف هذا، في شهر يوليو (جويلية)، ابتكر خبراء من جامعة هارفارد ومعمل أبحاث معهد ماساتشوستس للتكنولوجيا (مختبر IBM Watson Lab)، أداة قائمة على الذكاء الاصطناعي للكشف عن النص الناتج عن الخوارزمية. ومع ذلك، تظهر الأبحاث الحديثة التي أجرتها جامعة MIT، أن آلية تشغيل هذه الأداة لديها خطأ أساسي.
ويعتبر (Giant Language Model Room (GLTR عبارة عن نظام للكشف عن النص الذي تم إنشاؤه بواسطة الخوارزميات أو البشر. انحراف هذه الأداة هو أن النص الذي يكتبه البشر دقيق دائمًا، وأن المقالات المكتوبة بواسطة نظام الذكاء الاصطناعي كلها مزيفة. هذا يعني أنه حتى المقالات التي أنشأتها أنظمة الذكاء الاصطناعي والتي تحتوي على معلومات دقيقة ستظل تعرف بأنها أخبار مزيفة والعكس صحيح.
وبالإضافة إلى ذلك، يؤكد البحث أن المهاجم لديه القدرة على استخدام هذه الأداة لمعالجة النصوص البشرية. يمكنهم تدريب الذكاء الاصطناعي باستخدام نموذج GPT-2 لتغيير النص من صنع الإنسان لتشويه المعنى الأصلي.
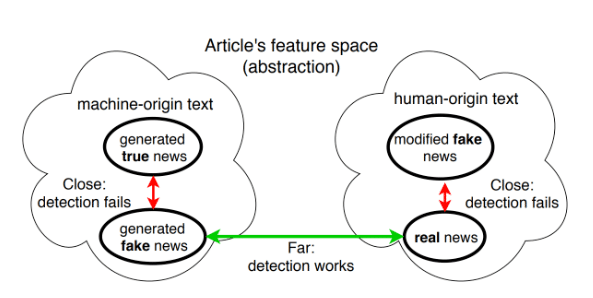
وأكد تال شوستر، المشارك الرئيسي في الدراسة، على أهمية اكتشاف صحة النص، وليس تحديد ما إذا كان المقال قد تم إنشاؤه بواسطة البشر أو عن طريق الخوارزميات. وقالت ريجينا برزيلاي، أستاذة في معهد ماساتشوستس للتكنولوجيا، إن البحث أظهر عدم مصداقية أدوات تصنيف المعلومات المضللة الحالية.
ولتصحيح الخطأ، استخدم الباحثون أكبر قاعدة بيانات في العالم للفحوصات الفعلية، لتطوير نظام كشف مزيف جديد. ومع ذلك، فإن النموذج الذي تم إنشاؤه عرضة للأخطاء بسبب انحرافات مجموعة البيانات.
وعندما أنشأ الفريق مجموعة بيانات جديدة عن طريق تصحيح الأخطاء، تم تخفيض دقة النموذج من 86 ٪ إلى 58 ٪. هذا يدل على أنه لا يزال هناك الكثير من العمل الذي يتعين القيام به لتدريب الذكاء الاصطناعى على البيانات.
ويعتقد الخبراء أن عيب أداة الكشف عن الأخبار المزيفة لا يستخدم الأدلة الواقعية الخارجية كجزء من عملية التحقق، ويأمل الفريق في تحسين هذا النموذج في المستقبل حتى يتمكن من اكتشاف أنواع وهمية من المعلومات من خلال الجمع بين آلية العمل الحالية والأدلة الواقعية.